




Table of contents
Introduction
A while back, I worked on building a client-server flight reservation system as part of my distributed systems class. The client handles user requests such as querying flight details before parsing these requests into data to be sent to the server, while the server takes in requests and executes the business logic accordingly.
However, I needed to strictly use UDP as the communication protocol and implement my own message format and marshaling protocol. Other than that, I am free to make any other decisions.
Although the initial server requirements only need to support multiple but non-concurrent users, in the spirit of freedom and Go's ever-so-famous-and-simple concurrency support, I made the liberal choice to build a server that supports concurrency!
In this post, I'll share my experiences in building the server using Go, including my design decisions, applying concurrency design patterns and the general challenges with concurrency programming. Also, I'll use and touch on important concepts that developers hold dear to heart like communication protocols, message formats, data representations, caching and more! If you are interested to find out more, keep reading!
Why use Go?
Out of all the fancy languages in the world, why did I choose to use Go to build a server? The answer is simple:
Abstraction via goroutines: Go's famous goroutines and concurrency patterns means I can leverage Go as a simple yet effective way to handle multithreaded concurrency
Simple and verbose low-level control: Go is perfect for producing a very performant piece of work in a reasonable amount of time
Why not: Trying things out is always important and Go has always been an itch I've been down to code with.
Designing the Distributed System
Overview
In a distributed system, a few of the most fundamental questions to ask are: How do we get messages across from A to B? and How do make sure the other party understands the message?
Communication protocols help answer the first question - they define rules that allow for data transmission within a network. Common examples are the connectionless protocol UDP focused on speed and the connectionful protocol TCP which uses a slower startup but guarantees reliability. These 2 are considered lower-level communication protocols that web developers don't often touch. Instead, we often use higher-level concepts such as HTTP or even higher-level concepts like REST, gRPC, JSON-RPC, etc that are built on top of it! In this design, UDP was chosen by default as it was one of the task requirements of the project.
Message formats or data formats help answer the second question. An example would be in web development, where we often deal with the JSON format when interacting with REST APIs. The JSON format has largely garnered so much popularity because it is simultaneously human-readable and machine-readable while maintaining a decent overhead in terms of space.
An interesting effect of having to implement the message format from scratch is having to also implement the marshaling process as well. Specifically, since UDP only sends and receives bytes, it is impossible to process logic on top of these bytes without understanding what they represent. Thus it is important to include a data representation to convert bytes into memory representations such as integers, strings and arrays and vice versa!
My Message Format
Since the message format will only be used for this project, there is no need to reimplement the JSON format and marshaling library from scratch. Instead, I can focus on a simple yet effective design that can sufficiently cover the necessary cases.
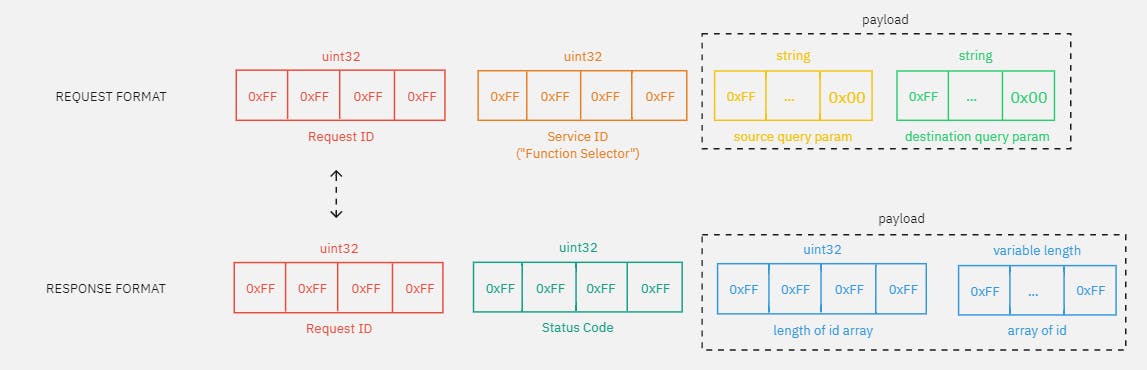
In any request or response, I split the datagram packet into 3 sections.
Request ID [4 bytes]
The request ID is an identifier used by the server to identify unique requests sent per user and also for user clients to match responses with requests. Here, it just needs to be big enough to avoid a request ID collision (2^32 per user)
The request ID is important because in UDP, requests and responses can be asynchronous and packets can be delivered out-of-order or even dropped. Thus the request ID can be leveraged to solve much confusion!
The practice of using a request ID is surprisingly very commonplace even in many message formats that guarantee delivery such as HTTP. For example, in JSON-RPC, the request ID is needed to differentiate batch requests where multiple fractional requests are sent in a single HTTP request!
Service ID [4 bytes]
The service ID is an identifier used by the server to identify the service function requested by the client. For example, to query a specific flight would have a service ID of 1 while booking a flight would have a service ID of 2.
Primarily, it just needs to be big enough to avoid a service ID collision (2^32 unique services). A simple way would be to use an incrementing function (e.g
service_id == 1refers toendpoint_1()), but an arguably better way would be to base the service ID on the function signature. This is because each service function takes a specific input format.For example, an endpoint that queries the flight details takes in a
flight_id uint32, this means the data returned might be different if the query wrongly uses auint64and in the worst case, the client won't be able to tell that the response is wrong! To avoid confusion, a possible way would be to hash the function selector signature and use the first 4 bytes as the service ID. (e.g performkeccak256ongetFlightById(uint32 flight_id))The practice of using service ID is also very commonplace, you would find it everywhere! However, the exact representation of the service ID varies here and there. (some even take in a string!)
Remaining payload [n bytes]
The remaining payload is of variable size and this represents the parameters that the service requires to execute business logic.
For example, to query all flights going from Singapore to USA, I need the airport codes of
source := "SIN"anddestination := "LAX"as parameters to call thegetFlightsservice function.
My Data representation
There are many different data types in Go but in my case, the server only requires integers, floats, strings and arrays. It is important to represent the request and response object containing these data in bytes as it should be language-agnostic, meaning a client made using another language like Java or Rust must be able to do the conversion without any hiccups.
I can reference the Common Data Representation (CDR) used typically for Common Object Request Broker Architecture (COBRA) distributed objects for my data representation. (Note it is not an exact copy for ease of implementation)
| Data type | Size | Representation |
| Integer | 4-bytes | uint32 |
| Float | 4-bytes | float64 |
| Array | 4-bytes + variable length * size of primitive | Array of primitives: With uint32 representing size of array + primitives in order |
| Char | 1-byte | Just 1 byte |
| String | 4-bytes + variable length | Array of char: uint32 representing size of char array + char in big-endian order |
Why is language-agnostic important?
Let's use an example to explain this. In Go, there are both signed and unsigned integers. However, in another language like Java, there are only signed integers! This means sending a uint32 in Go will be interpreted as i32 in Java. Thus, the marshaling process needs to be standardized instead of relying on the language's serialization libraries. Not doing so might break the data representation!
Standardizing the endianness of the data stream is also important as different machines work in little-endian or big-endian. Relying on the endianness of your machine for the system to function properly can break things and some even consider it an anti-pattern.
My Design
For the entire payload, I chose to have everything in big-endian (read from left to right). For example, the uint32 below is the max value 2^32 represented by hex values 0xFFFFFF.
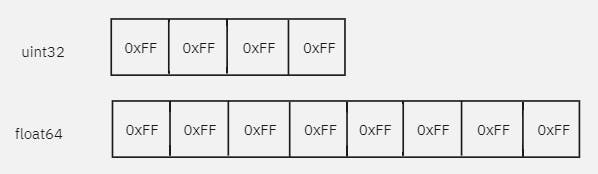
I chose to represent integers as a 32-bit unsigned integer uint32 as there are no use cases where a negative integer is needed. For floats, it is represented as 64-bit in size. The marshaling and unmarshalling processes are easy as I can put the integer or float into a byte array of size 4 or 8 to marshal and I can read the first 4 or 8 bytes to unmarshal.
func MarshalUint32(data uint32) []byte {
payload := make([]byte, 4)
binary.BigEndian.PutUint32(payload, data)
return payload
}
func UnmarshalUint32(data []byte) uint32 {
return uint32(binary.BigEndian.Uint32(data[:4]))
}
func MarshalFloat64(data float64) []byte {
buf := new(bytes.Buffer)
err := binary.Write(buf, binary.BigEndian, data)
if err != nil {
log.Println(err)
}
return buf.Bytes()
}
func UnmarshalFloat64(data []byte) float64 {
return math.Float64frombits(binary.BigEndian.Uint64(data))
}
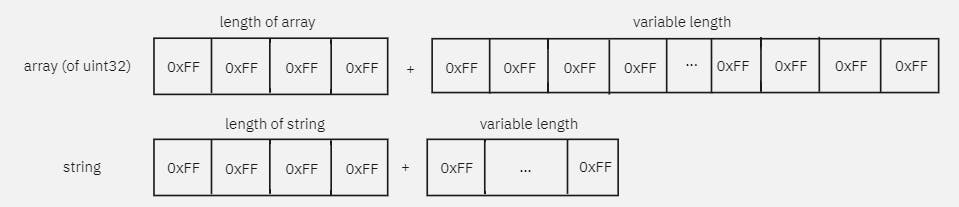
Arrays are more difficult to marshal and unmarshal as they can be of variable size. Thus, I chose to declare the size of the array as a uint32 first before marshaling each primitive in the exact order given in the array. To unmarshal an array, I need to unmarshal the first 4 bytes to get the size before procedurally unmarshalling each element in the array. Strings are just represented as an array of 1-byte elements instead of an array of primitives like a uint32 array! (Go does not have the concept of char)
func MarshalUint32Array(data []uint32) []byte {
lenData := len(data)
payload := make([]byte, 4+lenData*4)
copy(payload[:4], MarshalUint32(uint32(lenData)))
for i := 0; i < lenData; i++ {
copy(payload[4+i*4:8+i*4], MarshalUint32(uint32(data[i])))
}
return payload
}
func MarshalString(data string) []byte {
payload := bytes.Join([][]byte{MarshalUint32(uint32(len(data))), []byte(data)}, []byte{})
return payload
}
func UnmarshalString(data []byte) string {
lenData := UnmarshalUint32(data[:4])
return string(data[4 : 4+lenData])
}
Implementing the Server
Now that we have the design of the distributed system settled, let's dive into implementing the server in Go! For reference, you can find my implementation on github:
Overview
Step-by-step, the server works in this way from startup to serving a request:
Build necessary components (server, cache and router)
Binds & start listening on port
8888for UDP requestsRead ingress UDP datagrams -> create a goroutine to start serving the request
Get the IP address of the client and parse
reqId,serviceId, andpayloadConstruct a
cacheKeybased on thereqIdandipAddrand search the cache for duplicate requestsRespond with cached response if found, else route the request to handler functions corresponding to the
serviceIdIf no handler function exists, respond with an error message
If a handler function exists, execute the business logic
Construct the response object using the
payloadreturned from the handler function andreqIdfrom before.Using the
cacheKeyfrom before, cache the entire responseRespond with the response object
Service requirements
Firstly, let's go through some basic CRUD services the server provides:
Search all possible flights based on a source and destination location
Get all details and relevant metadata of a flight
Reserve
nseats of a flight
These are very basic functions that I'll then use to explain how I handle other issues that arise!
Handling concurrent requests
The first issue that the server needs to address is: How do we handle multiple requests coming in at the same time?
To answer that, there needs to be some sort of a queue mechanism to add tasks to a queue and get workers to run the task. And this is where Go's simplicity in concurrency implementation shines!
In Go, the simplest job queue is the built-in channels type in the standard library. For reference, you can refer to here on how Anthony GG used channels to create a TCP server. In my case, I would need to tailor a UDP version that suits my service functions as well.
type UDPServer struct {
ListenAddr string
quitch chan struct{}
MsgChannel chan Message
Ln net.UDPConn
}
func NewUDPServer(listenAddr string) *UDPServer {
return &UDPServer{
ListenAddr: listenAddr,
quitch: make(chan struct{}),
MsgChannel: make(chan Message, 10),
}
}
func (s *UDPServer) Start() error {
laddr, err := net.ResolveUDPAddr("udp", s.ListenAddr)
if err != nil {
log.Fatal(err)
}
ln, err := net.ListenUDP("udp", laddr)
if err != nil {
return err
}
defer ln.Close()
s.Ln = *ln
go s.readIngress(*ln)
<-s.quitch
close(s.MsgChannel)
return nil
}
I can build the server by calling NewUDPServer with listenAddr being the port to bind and listen on. Following which I can call Start() to begin listening. One requirement of a server is that the main goroutine needs to keep running and listening to requests until a signal such as SIGTERM or SIGINT is used to shut down the server. Thus, I can use an unbuffered channel quitch to block the goroutine and prevent it from shutting down.
In the main goroutine, every incoming UDP packet that is sent to ListenAddr is intercepted. Then, separate child goroutines are created for every request that is received. (I can create goroutines using just 1 line: go s.readIngress(*ln))
However, I still need a queue to order, share and store incoming UDP requests. Unlike quitch which is an unbuffered channel that blocks, I can use a buffered channel MsgChannel instead. A buffered channel means MsgChannel is not blocking and I can have other goroutines continually consume from the channel. To produce new tasks, I can populate the channel with a new Message containing the client's payload and IP address as shown below.
func (s *UDPServer) readIngress(conn net.UDPConn) {
defer conn.Close()
buf := make([]byte, 2048)
for {
n, addr, err := conn.ReadFromUDP(buf)
if err != nil {
log.Fatal((err))
continue
}
s.MsgChannel <- Message{
Sender: addr.String(),
Payload: buf[:n],
}
fmt.Println("New connection received from:", addr)
// _, err = conn.WriteToUDP([]byte("Processing request\n"), addr)
if err != nil {
log.Fatal(err)
continue
}
}
}
The key benefit that Go provides is that I do not need to worry about managing threads as the channel acts as a thread-safe FIFO queue and automatically becomes blocking (stops accepting incoming packets) when it exceeds the maximum channel size and will only start accepting again once the channel is no longer full. This prevents the server from overloading and having its resources completely exhausted.
That's all I need to do to build a UDP server that supports concurrency using Go! It's really simple and fast!
Storing data
Since I have implemented a concurrent server, I also need a database that can handle concurrency! This is to prevent multiple concurrent writes from triggering a race condition in the database. Typically, I would use a persistent database to store all this information but since this project is focused on communication protocols and not data persistence, values can be stored in memory for now.
A simple and naive solution would be to use a hashmap and leverage Go's sync.Mutex lock to lock the database whenever a read or write process is being performed. However, we all know from our database engineering classes that locking an entire database is rather slow in general and might end up causing more problems than it solves. (ahem MongoDB before WiredTiger)
On the other hand, creating my own in-memory database with its own row and column locks to handle concurrency is another very complex issue for another day... Instead, I can just use an in-memory database go-memdb built by Hashicorp that does this for me.
Creating the database is easy, I just need to state the appropriate schemas and index the database accordingly and bootstrap it with a bunch of artificial data for testing and it's done! I love Hashicorp <3.
type Flight struct {
id uint32
source string
destination string
departureTime time.Time
price float64
seatsLeft uint32
seats map[uint32]Seat
subs []Subscriber
}
type Subscriber struct {
listenAddr string
endTime time.Time
}
type Seat struct {
reserved bool
buyer string
}
type FlightDatabase struct {
db *memdb.MemDB
}
func NewDatabase(timeout time.Duration) (*FlightDatabase, error) {
_, cancel := context.WithTimeout(context.Background(), timeout)
defer cancel()
schema := &memdb.DBSchema{
Tables: map[string]*memdb.TableSchema{
"flights": &memdb.TableSchema{
Name: "flights",
Indexes: map[string]*memdb.IndexSchema{
"id": &memdb.IndexSchema{
Name: "id",
Unique: true,
Indexer: &memdb.UintFieldIndex{Field: "id"},
},
"source": &memdb.IndexSchema{
Name: "source",
Unique: false,
Indexer: &memdb.StringFieldIndex{Field: "source"},
},
"destination": &memdb.IndexSchema{
Name: "destination",
Unique: false,
Indexer: &memdb.StringFieldIndex{Field: "destination"},
},
},
},
},
}
db, err := memdb.NewMemDB(schema)
if err != nil {
log.Fatal(err)
return nil, err
}
boostrapDatabase(db)
return &FlightDatabase{db: db}, nil
}
Caching responses
A key issue that using UDP presents is that it is a connectionless protocol. Thus, some packets can be delivered out-of-order or even lost in transmission. As reliability is not guaranteed in the transport layer, the application needs to handle this.
In my case, a single request and response is determined by a round-trip from the client. If a response is not received after a 1-second timeout, clients will have to re-ping the same request to the server. This ensures reliability as a response will eventually be returned.
However, this design produces another issue: functions can be run more than once. This is known as the at-least-once invocation semantic and can cause problems because some service functions modify the state of the database which ultimately causes unintended outcomes when duplicate requests are fired.
In the case of querying the details of a flight, the query itself does not change the state of the database. Thus, users can keep querying the same request without having any implications. This is an idempotent operation as making additional identical requests do not have an unintended effect on the server.
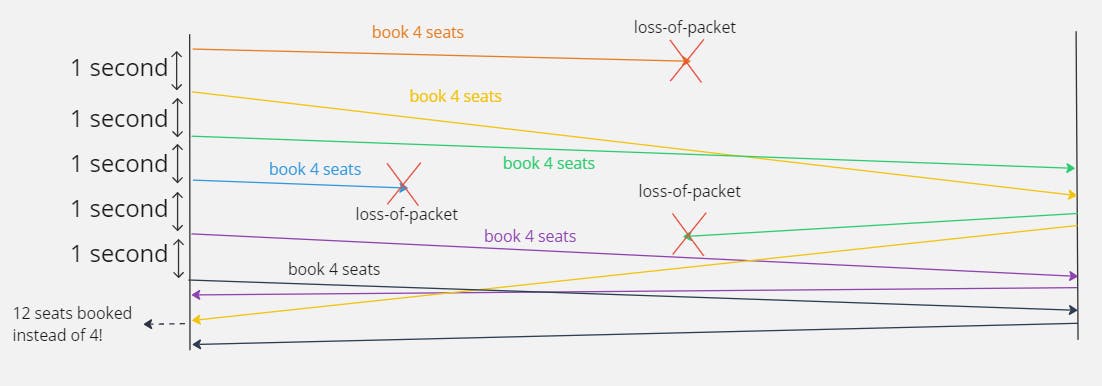
However, not all requests are idempotent! For example, to book a flight, I need to give the number of seats n desired. This means that in an event of a delayed packet or a loss in transmission, we could end up sending multiple requests that could make multiple unintended bookings! Additional identical requests that cause unintended effects on the server are non-idempotent operations.
To avoid these bad outcomes, I can use the at-most-once invocation semantic instead. In other words, if a request is being processed or has been processed, the server will not process the duplicate request and simply return the intended response. A simple way of doing this would be to cache these requests and responses. For the server, I decided to use bigcache which provides me with a performant and concurrent in-memory cache.
type ResponseManager struct {
manager bigcache.BigCache
}
func NewResponseManager() *ResponseManager {
responseManager, _ := bigcache.New(context.Background(), bigcache.DefaultConfig(10*time.Minute))
return &ResponseManager{
manager: *responseManager,
}
}
func (responseManager *ResponseManager) GetHashKey(reqId uint32, user string) []byte {
hasher := xxhash.New()
hasher.Write([]byte(user))
hash := hasher.Sum64()
hash ^= uint64(reqId)
hashKey := make([]byte, 12)
binary.LittleEndian.PutUint64(hashKey[:8], hash)
binary.LittleEndian.PutUint32(hashKey[8:], reqId)
return hashKey
}
I use the same builder pattern as the UDP server to create my ResponseManager. In caches, it's important to use a key-value pair store for performant reads. Thus, I can take the IP address of the client user and the reqId, do some string hashing and bit-shifting magic to generate a hashKey and then use this key to cache the response!
Now, I just need functions to get and set new keys in the cache for the goroutines to invoke and now when a duplicate request is received, it just returns the cached response. Catastrophe avoided phew!
How long should I cache responses?
One big question you might be wondering is: How long should I cache responses?
Honestly, I don't think there's a hard and fast rule for this... Some argue that the responses should be cached for eternity, but I don't really think it is a good idea to use system memory to do that. On top of having a lot of stale data in your cache which can cause in-memory writes to become a bit slower, caching for eternity would also eat up valuable RAM that is needed for executing business logic. Additionally, RAM is very expensive in general for server deployments and I would want to avoid spending unnecessary money.
I guess this question is a matter of balance between user experience and server cost. I decided to cache the responses with a time-to-live (TTL) of 10 minutes based on some rough math:
In my distributed system, clients are expected to send the same request every second if no response is returned.
Once the first request succeeded, the client can send up to 600 requests in the next 10 minutes to get a response from the server.
Assuming an error rate of 1%, this means that the chances of a request being executed but a response failing to reach is negligibly 0 (roughly 0.02^600 -> the packet can fail in a round-trip)
Of course, this is not a fit-all solution since we have to take into account how long each request takes to execute, whether we are expecting users to query for their seats by sending an identical booking request again a few weeks later or should we have an idempotent request to query for such data, can we store stale data in a persistent database instead, etc.
Conclusion
And finally, we have come to the end!
With this being my first experience designing a distributed system and also my first time using Go, I have to say that the Go experience truly lives up to what Gophers describe it to be!
Many stumbling blocks can happen when trying to build a distributed system and the way Go simplifies the entire issue of thread-safe concurrency with its set of concurrency tools makes it quick to build a concurrent system in a very reasonable amount of time. On top of that, the very extensive standard library and high-quality libraries built on top mean that it's really easy to find the tools you need - and if you can't find them, you can easily build them!
I am already using Go to build other projects and am very interested to see what other things I can do with it! I would strongly recommend a tour of Go if you're just getting started with Go and there's a whole bunch of resources from GopherCon SG and Anthony GG if you're trying to pick up the concurrency concepts and deep-dive into Go!